배경
회사 국내 웹사이트를 신규 개발하면서 도메인이 바뀌게 되었습니다.
- 기존:
https://smartscore.kr - 변경:
https://smartscore.global/kr/ - 해외:
https://smartscore.global/{country_code}/
도메인이 바뀐다는 건 구글 입장에서 새로운 사이트가 생긴 것과 같습니다. 기존 smartscore.kr 에 쌓여 있던 검색 색인은 새 URL로 자동으로 넘어오지 않습니다. 배포 이후 검색 노출이 뚝 떨어질 수 있는 상황이었습니다.


SEO 작업을 직접 해본 적이 없어서, 뭘 어떻게 해야 하는지부터 파악하는 것이 먼저였습니다. 이것저것 찾아보면서 체크리스트를 만들고 하나씩 해결해나갔습니다.
1. 서치 콘솔 등록
구글과 네이버 두 곳에 사이트를 등록해야 했습니다.
구글 서치 콘솔
소유권 인증 방식은 다음과 같이 여러 가지가 있었습니다.
- HTML 파일 업로드
- HTML 메타 태그 추가
- DNS TXT 레코드 추가
- Google Analytics 연동
HTML 파일 업로드나 메타 태그 방식은 배포 파이프라인을 거쳐야 했습니다. 반면 DNS TXT 레코드 방식은 배포 없이 인프라팀에 요청해서 처리할 수 있었기에 이 방법을 적용해 빠르게 처리할 수 있었습니다.

네이버 서치 어드바이저
여기서 예상 못한 문제가 생겼습니다. 네이버는 사이트를 호스트 단위로만 등록할 수 있습니다. smartscore.global 로 등록하면 /kr/, /en/, /jp/ 등 국가 코드가 다른 경로들이 전부 한 묶음이 됩니다. 국내 사이트와 해외 사이트를 분리해서 관리할 수 없다는 뜻입니다. 구글에 비해 세밀한 관리가 어렵다는 것을 여기서 조금 느꼈습니다.
2. 사이트맵 작성 및 제출
크롤러는 링크를 따라가며 페이지를 발견합니다. 사이트맵은 크롤러에게 "이 사이트에는 이런 페이지들이 있다"고 직접 알려주는 XML 파일입니다. 신규 사이트일수록 사이트맵이 중요합니다. 내부 링크가 없는 페이지는 크롤러가 발견하지 못할 수도 있기 때문입니다.
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>https://smartscore.global/kr/</loc>
<changefreq>yearly</changefreq>
<priority>1.0</priority>
</url>
<url>
<loc>https://smartscore.global/kr/tech</loc>
<changefreq>yearly</changefreq>
<priority>0.8</priority>
</url>
<url>
<loc>https://smartscore.global/kr/platform</loc>
<changefreq>yearly</changefreq>
<priority>0.8</priority>
</url>
<url>
<loc>https://smartscore.global/kr/about-us</loc>
<changefreq>yearly</changefreq>
<priority>0.8</priority>
</url>
<url>
<loc>https://smartscore.global/kr/contact-us</loc>
<changefreq>yearly</changefreq>
<priority>0.8</priority>
</url>
</urlset>
작성 후 구글 서치 콘솔과 네이버 서치 어드바이저에 제출했습니다. changefreq는 크롤러에게 얼마나 자주 콘텐츠가 바뀌는지 힌트를 주는 값이고, priority는 같은 사이트 내에서 어떤 페이지가 더 중요한지 상대적인 우선순위를 나타냅니다.
3. robots.txt 작성
robots.txt는 크롤러의 접근을 제어하는 파일입니다. 크롤링을 허용할 봇과 허용하지 않을 봇, 허용할 경로와 그렇지 않은 경로를 지정할 수 있습니다.
작성하면서 헷갈렸던 부분이 있었습니다. 아래처럼 쓰면 *로 전체를 차단했는데 Googlebot이 접근할 수 있을지 의문이었습니다.
# 모든 크롤러 기본 차단
User-agent: *
Disallow: /
# 주요 검색엔진만 허용
User-agent: Googlebot
User-agent: Googlebot-image
User-agent: Bingbot
User-agent: Yeti
User-agent: NaverBot
User-agent: Daum
User-agent: Daumoa
User-agent: kakaotalk-scra
Allow: /
Sitemap: https://smartscore.global/kr/sitemap.xml
찾아보니 robots.txt의 규칙은 위에서 아래로 순서대로 적용되는 게 아닙니다. 각 봇은 자신과 일치하는 User-agent 그룹의 규칙만 따릅니다. Googlebot은 User-agent: * 그룹이 아니라 User-agent: Googlebot 그룹의 규칙을 사용합니다. 특정 봇 전용 그룹이 없는 봇만 * 규칙을 따릅니다. 처음에 이 동작 방식이 직관적이지 않아서 한참 찾아봤습니다.
4. 메타데이터 동적 관리
SPA의 가장 큰 SEO 한계 중 하나가 여기 있습니다. 전통적인 서버 렌더링 방식은 요청마다 서버에서 HTML을 만들어 보내기 때문에, 크롤러가 가져가는 HTML에 페이지에 맞는 <title>, <meta description> 같은 정보가 이미 들어있습니다.
그런데 Vue SPA는 HTML이 하나입니다. 라우터로 어떤 페이지를 보든 처음 받는 HTML은 동일합니다. 그래서 JavaScript를 이용해 <head>를 동적으로 조작해야 합니다.
라이브러리 선택
이 문제를 해결하는 라이브러리를 찾아봤습니다.
| 라이브러리 | 마지막 업데이트 | 비고 |
|---|---|---|
| vueuse/head | 2년 전 | 유지보수 중단 |
| vue-meta | 5년 전 | 유지보수 중단 |
| Unhead | 5일 전 (2025.03 기준) | SSR/CSR 모두 지원 |
유지보수가 중단된 라이브러리를 도입하면 나중에 버전 충돌이나 보안 이슈가 생겨도 대응할 방법이 없기 때문에, 유지보수가 활발한 Unhead를 선택했습니다.
기본 설정
<!-- index.html: head 태그는 최소한으로만 -->
<!DOCTYPE html>
<html lang="ko">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<link rel="icon" href="/favicon.ico" />
</head>
<body>
<div id="app"></div>
<script type="module" src="/src/main.js"></script>
</body>
</html>
// main.js
import { createApp } from "vue";
import App from "./App.vue";
import router from "./router";
import { createHead } from "@unhead/vue/client";
const app = createApp(App);
const head = createHead();
app.use(router);
app.use(head);
app.mount("#app");
라우터에서 공통 관리
각 페이지 컴포넌트에서 개별 호출하는 방식도 있지만 저는 라우터의 meta 속성에 타이틀과 설명을 선언해두고 afterEach 에서 한 번에 처리하는 방식으로 통합했습니다. 이 방법은 관리 포인트가 분산되지 않아 훨씬 깔끔하고 나중에 타이틀을 바꿔야 할 때 라우터 파일 하나만 보면 되는 장점이 있습니다.
// router/routing/index.js
const Home = {
path: "/",
name: "HomeView",
component: () => import("@/pages/HomeView.vue"),
meta: {
title: "스마트스코어 | 골프 예약 플랫폼",
description: "국내 370개 골프장 예약 서비스",
},
};
// router/index.js
import { createRouter, createWebHistory } from "vue-router";
import routing from "./routing";
import { useHead } from "@unhead/vue";
const router = createRouter({
history: createWebHistory(import.meta.env.BASE_URL),
routes: routing,
});
router.afterEach((to) => {
if (to.meta?.title) {
useHead({
title: to.meta.title,
meta: [
{ name: "description", content: to.meta.description || "" },
{ property: "og:title", content: to.meta.title },
{ property: "og:description", content: to.meta.description || "" },
{
property: "og:url",
content: `https://smartscore.global${to.fullPath}`,
},
],
});
}
});
export default router;
beforeEach가 아닌 afterEach를 선택한 이유는, 라우트 이동이 확정된 이후에 메타데이터를 업데이트해야 하기 때문입니다. beforeEach는 네비게이션 가드에서 리다이렉트나 취소가 발생할 수 있어서, 실제로 이동이 완료된 시점인 afterEach가 더 적절합니다.
5. 구조화 데이터 추가
구글은 Schema.org 형식의 구조화 데이터를 읽어서 검색 결과에 추가 정보를 표시할 수 있습니다. 리치 스니펫이라고도 부르는데, 검색 결과에서 별점, 리뷰 수, 가격 같은 추가 정보가 보이는 게 이 덕분입니다.
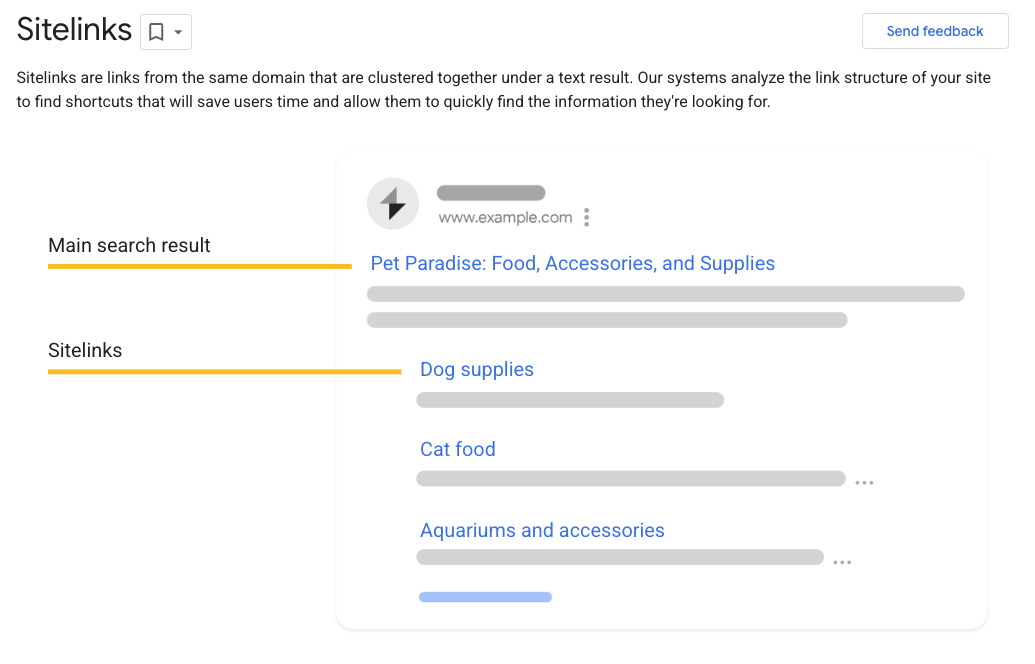
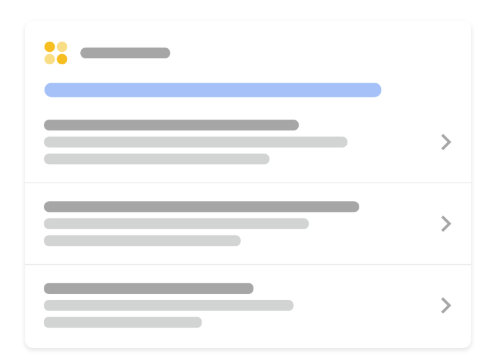
BreadcrumbList 스키마를 index.html에 추가해 현재 페이지의 계층 구조를 구글에 전달했습니다.

<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "BreadcrumbList",
"itemListElement": [
{
"@type": "ListItem",
"position": 1,
"name": "Golf Tech",
"url": "https://smartscore.global/kr/tech"
},
{
"@type": "ListItem",
"position": 2,
"name": "Golf Platform",
"url": "https://smartscore.global/kr/platform"
},
{
"@type": "ListItem",
"position": 3,
"name": "About Us",
"url": "https://smartscore.global/kr/about-us"
},
{
"@type": "ListItem",
"position": 4,
"name": "제휴 문의하기",
"url": "https://smartscore.global/kr/contact-us"
}
]
}
</script>
6. 결과
- SEO 로컬 테스트: 100점
- SEO 상용 배포: 83점 → 92점
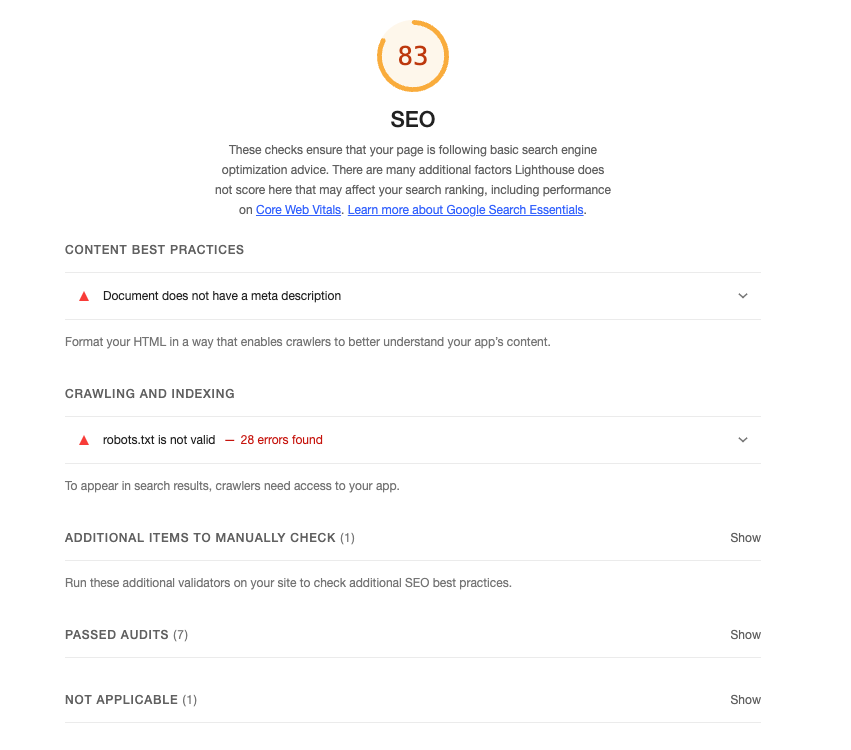
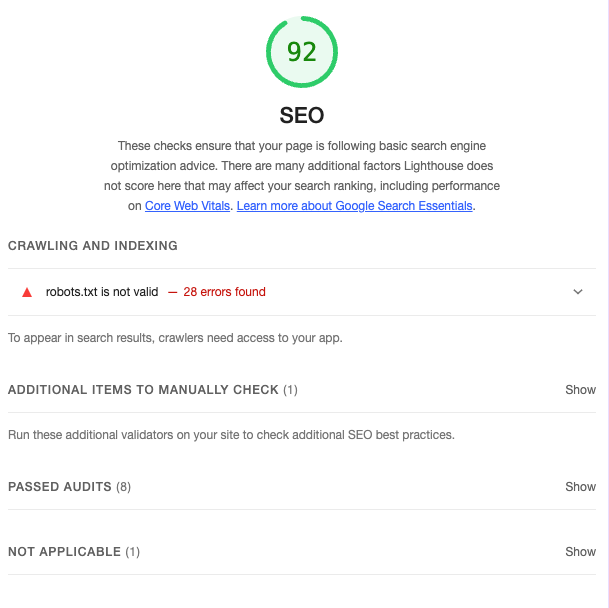
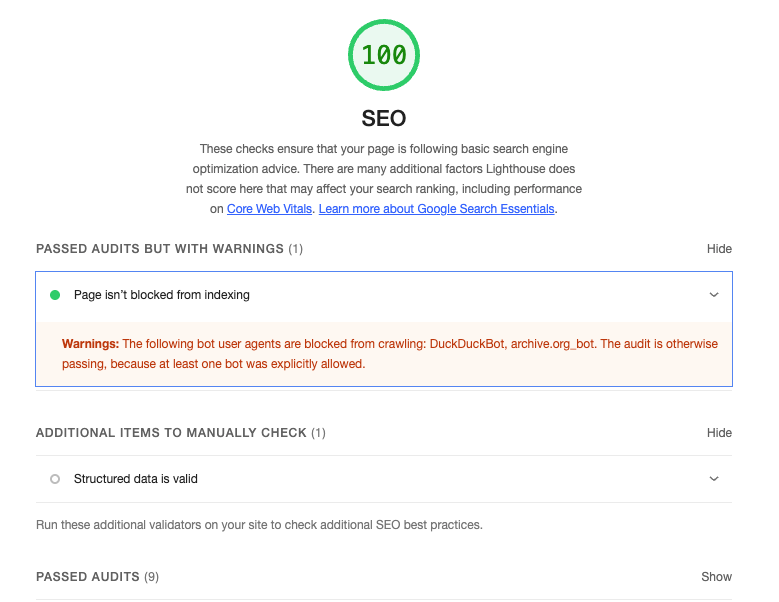
실제 검색 결과에 노출되기까지는 시간이 걸립니다. 크롤러가 사이트를 재방문하고 색인을 업데이트하는 주기가 있기 때문입니다. 지금은 서치 콘솔에서 크롤링 현황을 모니터링하는 중입니다.
마무리
작업을 하면서 SEO를 단순히 "키워드 넣는 작업"으로 생각했던 게 좁은 시각이었다는 걸 알게 됐습니다. 크롤러가 사이트를 어떻게 발견하고, 어떤 순서로 읽고, 어떤 정보를 가져가는지 그 흐름을 이해하는데 도움이 많이 되는 작업이었습니다.
robots.txt 하나만 해도 생각보다 동작 방식이 섬세했고, SPA에서 메타데이터를 다루는 건 서버 렌더링과 근본적으로 다른 접근이 필요했습니다. 처음부터 직접 세팅해보지 않았다면 계속 표면만 알고 넘어갔을 부분들이었다고 생각합니다.
SEO는 한 번 설정하면 끝이 아닙니다. 서치 콘솔에서 크롤링 오류가 없는지, 페이지가 잘 색인되고 있는지 꾸준히 봐야 합니다. 이번 기회에 그 흐름 자체를 파악했으니 앞으로 다른 프로젝트에서는 좀 더 쉽게 접근할 수 있을 것 같습니다.